
In-Memory Optimized Tables در Sql Server
گاهی اوقات وقتی می خواهم درباره مفهومی یاد بگیرم مغز من همه چیز را در مورد آن مسدود می کند. صحبت کردن درباره هر چیزی که از مفهوم In-Memory استفاده می کند ، گاهاً این کار را با من انجام می دهد. توجه به این نکته مهم است که In-Memory یک اصطلاح بازاریابی برای مجموعه ای از ویژگی ها در SQL Server است که رفتارهای مشترکی دارند اما ذاتاً با هم ارتباط ندارند. در این مقاله ، من قصد دارم برخی از مفاهیم In-Memory را توضیح دهم زیرا مربوط به SQL Server است که با غواصی در جداول بهینه شده در حافظه یا OLTP در حافظه شروع می شود. من قبلاً در مورد Columnstore نوشته ام که موارد استفاده نسبت به In-Memory OLTP بسیار متفاوت است و مواردی را می توانید در اینجا پیدا کنید . Columnstore نمونه کاملی از مفهوم In-Memory است که مدتی طول کشید تا سرم را به دور آن بپیچم.
جداول بهینه شده برای حافظه چیست؟
یک جدول بهینه شده برای حافظه ، که از SQL Server 2014 شروع می شود ، به سادگی جدولی است که دارای دو نسخه ، یکی در حافظه فعال و دیگری با دوام روی دیسک اعم از داده یا فقط طرحواره است ، که بعداً توضیح خواهم داد. از آنجا که با شروع مجدد سرویس های SQL حافظه شسته می شود ، SQL Server نسخه ای فیزیکی از جدول را که قابل بازیابی است ، نگه می دارد. حتی اگر دو نسخه از جدول وجود دارد ، نسخه حافظه برای شما کاملاً شفاف و پنهان است.
مزیت اضافه شده برای استفاده از این جداول حافظه چیست؟
این همیشه چیزی است که هنگام بررسی گزینه ها یا ویژگی های SQL Server می پرسم. برای جداول درون حافظه ، روشی است که SQL Server قفل ها و قفل ها را کنترل می کند. طبق گفته مایکروسافت ، این موتور از رویکردی خوش بینانه برای این امر استفاده می کند ، به این معنی که قفل یا قفل را روی هر نسخه از ردیف های داده به روز شده قرار نمی دهد ، که بسیار متفاوت از جداول عادی است. این مکانیزم است که اختلافات را کاهش می دهد و به پردازش ها اجازه می دهد تا سریعتر پردازش شوند. به جای قفل ، In-Memory با استفاده از Row Versions ، ردیف اصلی را تا بعد از انجام معامله حفظ می کند. دقیقاً مانند Read Committed Snapshot Isolation (RCSI) ، این امکان را برای تراکنش های دیگر فراهم می کند تا ضمن به روزرسانی نسخه ردیف جدید ، ردیف اصلی را بخوانند. نسخه ساختار در حافظه است pageless و بهینه سازی شده برای سرعت در حافظه فعال ، بسته به میزان کار ، تأثیر قابل توجهی در عملکرد دارد.
Sql server همچنین ثبت گزارش خود را برای این جداول تغییر می دهد. به جای ورود کامل ، این دوگانگی هر دو نسخه دیسک و حافظه (نسخه های ردیفی) جدول امکان ورود کمتر را فراهم می کند. SQL Server می تواند از نسخه های قبل و بعد برای دستیابی به اطلاعاتی که معمولاً از یک پرونده ورود به دست می آورد ، استفاده کند. در SQL Server 2019 ، همین مفهوم در مورد رویکرد جدید بازیابی سریع (ADR) برای ورود به سیستم و بازیابی نیز صدق می کند .
سرانجام ، یکی دیگر از مزایای اضافه شده ، DURABILITYگزینه ای است که در مثال در بخش ایجاد جداول نشان داده شده است. استفاده از SCHEMA_ONLYمی تواند یک روش عالی برای استفاده از جداول # TEMP و افزودن روشی کارآمدتر برای پردازش داده های موقتی خصوصاً با جداول بزرگتر باشد.
مواردی که باید در نظر گرفت
اکنون همه اینها عالی به نظر می رسند ، بنابراین شما فکر می کنید که همه این موارد را به تمام جداول خود اضافه می کنند ، با این حال ، مانند تمام گزینه های SQL Server ، این برای همه محیط ها منظور نیست. مواردی وجود دارد که باید قبل از اجرای In Memory Tables در نظر بگیرید. قبل از در نظر گرفتن این ، ابتدا و مهمترین مقدار حافظه و پیکربندی آن حافظه را در نظر بگیرید. شما باید این تنظیمات را به درستی در SQL Server انجام دهید و همچنین برای افزایش استفاده از حافظه تنظیم کنید که ممکن است به معنای اضافه کردن حافظه بیشتر به سرور شما قبل از شروع باشد. ثانیا ، بدانید که مانند شاخص های Columnstore ، این جداول برای همه موارد قابل استفاده نیستند. این جدول برای WRITE با حجم بالا بهینه شده است ، نه یک انبار داده که بیشتر برای مثال برای خواندن است. در آخر اینکه لیست کاملی از ویژگی های پشتیبانی نشده و نحو را در نظر بگیرید ، حتما "را ببینیداسناد زیر فقط چند مورد است.
ویژگی هایی که در جدول های حافظه پشتیبانی نمی شوند را بخاطر داشته باشید.
- تکثیر
- آینه کاری
- سرورهای پیوند داده شده
- ورود به سیستم فله
- راه اندازهای DDL
- حداقل ورود به سیستم
- ضبط داده را تغییر دهید
- متراکم سازی داده ها
T-SQL پشتیبانی نمی شود:
- کلیدهای خارجی (فقط می توان به سایر PK های جدول بهینه سازی شده در حافظه اشاره کرد)
- جدول تغییرات
- ایجاد شاخص
- جدول TRUNCATE
- قابل بررسی DBCC
- DBCC CHECKDB
ایجاد یک جدول بهینه شده برای حافظه
کلید داشتن جدول "In-Memory" استفاده از کلمه کلیدی "MEMORY-OPTIMIZED" در بیانیه ایجاد هنگام ایجاد جدول است. توجه داشته باشید که توانایی تغییر جدول برای ایجاد بهینه سازی حافظه موجود وجود ندارد. برای استفاده از این گزینه در جدول موجود ، باید جدول را دوباره ایجاد کنید و داده ها را بارگیری کنید. فقط چند تنظیم دیگر وجود دارد که باید برای انجام این کار پیکربندی کنید همانطور که از زیر می بینید.
اولین قدم این است که مطمئن شوید در سطح سازگاری>> 130 هستید. برای اطلاع از سطح سازگاری فعلی سوال را اجرا کنید:
SELECT d.compatibility_level
FROM sys.databases as d
WHERE d.name = Db_Name();
اگر پایگاه داده در سطح پایین تری باشد ، باید آن را تغییر دهید.
ALTER DATABASE AdventureWorks2016CTP3
SET COMPATIBILITY_LEVEL = 130;
در مرحله بعدی شما باید پایگاه داده خود را تغییر دهید تا با فعال کردن MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOTتنظیمات از OLTP در حافظه استفاده کنید.
ALTER DATABASE AdventureWorks2016CTP3
SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON
سرانجام ، پایگاه داده شما باید یک گروه پرونده بهینه شده برای حافظه اضافه کند.
ALTER DATABASE AdventureWorks2016CTP3
ADD FILEGROUP AdventureWorks2016CTP3_mod CONTAINS MEMORY_OPTIMIZED_DATA
توجه داشته باشید که یک پایگاه داده ممکن است فقط یک گروه پرونده بهینه شده برای حافظه داشته باشد و پایگاه داده AdventureWorks2016CTP3 از قبل یک پایگاه داده دارد ، بنابراین هنگام اجرای این دستور ممکن است خطایی مشاهده کنید.
دستور زیر پرونده را در گروه پرونده جدید ایجاد می کند.
ALTER DATABASE AdventureWorks2016CTP3
ADD FILE (name='AdventureWorks2016CTP3_mod1',
filename='c:\data\AdventureWorks2016CTP3)
TO FILEGROUP AdventureWorks2016CTP3_mod
حالا یک جدول درست کنید:
USE AdventureWorks2016CTP3
CREATE TABLE dbo.InMemoryExample
OrderID INTEGER NOT NULL IDENTITY
PRIMARY KEY NONCLUSTERED,
ItemNumber INTEGER NOT NULL,
OrderDate DATETIME NOT NULL )
WITH
(MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA);
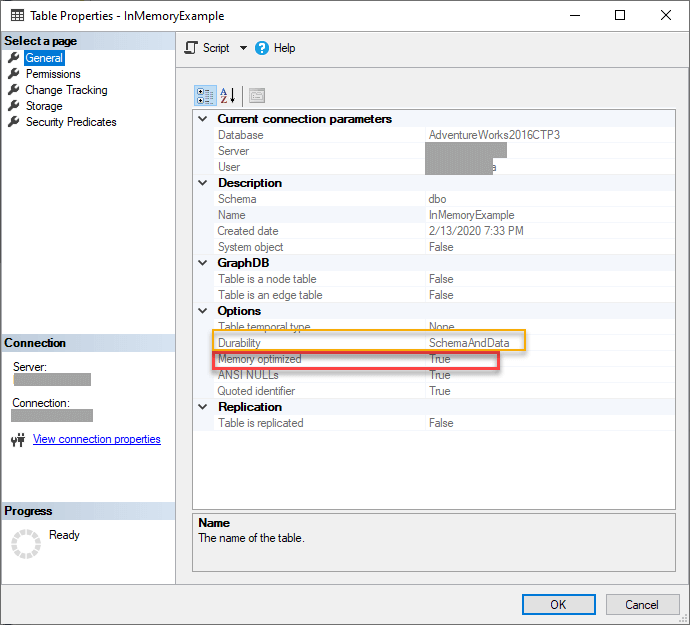
Table properties show Memory Optimized = TRUE and Durability = SchemaAndData once the table is created which makes it very simple to verify what the table is doing.
HASH شاخص های غیر عادی
از این فهرست برای دسترسی به نسخه In-Memory جدول استفاده می شود که Hash نامیده می شود. اینها برای پیش فرضهایی که جستجوی یکتایی هستند و دامنه مقادیر نیستند عالی هستند. اینها برای جستجوی ارزشهای برابری بهینه شده اند. به عنوان مثال ، WHERE Name = 'جو'. نکته ای که باید در هنگام تعیین اینکه چه چیزی باید در فهرست های شما درج شود به خاطر داشته باشید این است: اگر جستجوی شما دارای دو یا چند قسمت به عنوان محمول شما باشد و فهرست شما فقط از یکی از این زمینه ها تشکیل شده باشد ، اسکن خواهید شد. این بخش در آن زمینه گنجانده نخواهد شد. درک میزان کار و نمایه سازی در زمینه های مناسب (یا ترکیبی از آنها) مهم است. با توجه به اینکه این OLTP در حافظه عمدتا بر روی بارهای سنگین درج / به روزرسانی متمرکز است و کمتر به عنوان خوانده شده ، این مسئله نگرانی چندانی نخواهد داشت.
ین نوع شاخص ها بسیار بهینه شده اند و اگر مقادیر تکراری زیادی در یک شاخص وجود داشته باشد ، خیلی خوب کار نمی کنند ، هرچه مقادیر منحصر به فرد شما بهتر از عملکرد شاخص باشد ، به دست می آورید. دانستن اطلاعات خود همیشه مهم است.
وقتی نوبت به این شاخص ها می رسد ، دانستن میزان مصرف حافظه شما نقشی اساسی دارد. نوع شاخص هش ، طول ثابت است و مقدار مشخصی از حافظه را که هنگام ایجاد تعیین می شود ، مصرف می کند. مقدار حافظه توسط مقدار Bucket Count تعیین می شود. بسیار مهم است که مطمئن شوید این مقدار تا حد ممکن دقیق است. اندازه مناسب این عدد می تواند عملکرد شما را از بین ببرد. به گفته مایکروسافت ، تعداد بسیار کم آن "می تواند به میزان قابل توجهی بر عملکرد بار و زمان بازیابی پایگاه داده تأثیر بگذارد."
استفاده از T-SQL (هر دو روش نتیجه یکسانی دارند)
شاخص های غیر عادی
برای دستیابی به نسخه In-Memory جدول از شاخص های غیرمجاز نیز استفاده می شود ، با این وجود ، این مقادیر برای مقادیر دامنه مانند کمتر و برابر با ، پیش بینی های نابرابری و ترتیب های مرتب سازی شده بهینه شده اند. به عنوان مثال WHERE DATE بین "20190101" و "20191231" و WHERE DATE <> "20191231" است. این نمایه ها به تعداد سطل یا مقدار حافظه ثابت نیاز ندارند. حافظه مصرف شده توسط این شاخص ها با تعداد واقعی ردیف و اندازه ستون های کلید نمایه شده تعیین می شود که ایجاد آن را ساده تر می کند.
علاوه بر این ، بر خلاف شاخص های هش که برای جستجوی نیاز به تمام زمینه های مورد نیاز برای محمول شما بخشی از فهرست شما هستند ، اینها ندارند. اگر پیش بینی های شما بیش از یک قسمت داشته باشند و شاخص شما یکی از موارد اصلی را به عنوان کلید اصلی شاخص اصلی خود داشته باشد ، پس همچنان می توانید به یک جستجو برسید.
استفاده از T-SQL (هر دو روش نتیجه یکسانی دارند)
مثال اول (توجه داشته باشید که شاخص بعد از قسمت های جدول قرار می گیرد)
CREATE TABLE [Sales]
([ProductKey] INT NOT NULL,
[OrderDateKey] [int] NOT NULL,
INDEX IDX_ProductKey ([ProductKey]))
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
مثال دو (توجه داشته باشید که شاخص بعد از قسمت می آید)
CREATE TABLE [Sales]
([ProductKey] INT NOT NULL INDEX IDX_ProductKey,
[OrderDateKey] [int] NOT NULL)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
تعیین نوع شاخص برای استفاده می تواند مشکل باشد اما مایکروسافت یک راهنمای عالی در نمودار زیر ارائه داده است.
نتیجه
همانطور که مشاهده می کنید در مقایسه با شاخص های دیسک معمولی تفاوت های اساسی در نحوه کارکرد فهرست های جدول حافظه ، شاخص های بهینه سازی شده حافظه وجود دارد. قبل از شروع یا ایجاد جداول بهینه سازی شده برای حافظه ، مانند هر طراحی جدول دیگر ، در نظر گرفتن نیازهای شاخص خود بسیار مهم است. خوشحال خواهید شد که این کار را کردید.
توضیحات خود را بنویسید